「みんな大好きGooglebot☆」とは限らない

今や日本の検索エンジンシェア97%を誇るGoogle。
サイト制作者にとってGooglebotのアクセスは天使の来訪です。
しかしGooglebotはあくまでプログラム。訪れて欲しくないページやファイルにまで縦横無尽にアクセスしていきます。
そんな小悪魔なGooglebotを手懐けるrobots.txtの書き方と、Googlebotが正しく解釈しているか調べることのできるrobots.txtテスターについて解説します。
目次
robots.txtとは
robots.txtの記述方法
robots.txtのアップロード
「robots.txt テスター」を利用してrobots.txtの動作をテスト
WordPressのrobots.txtについて
PukiWikiのrobots.txtについて
robots.txtとは
robots.txt(ロボッツテキスト)とはWebクローラーに対して、特定のページをインデックスに登録しないように指定するファイルです。
以下の様なページはインデックスに登録させないことが推奨されます
- 1.ログインしたユーザーにのみ表示するページ
- 2.サイト内の検索結果ページや、カテゴリ一覧、タグ一覧など、コンテンツが重複するページ
WordPressで言えばログイン時の「/wp-admin」ディレクトリ。検索時の「?s=hoge」ページなどです。
インデックスに登録されたページの重複を解消できれば、分散していたページの重要度が1つに集約されるため、SEO的にも有利に働きます。
robots.txtに関する注意点 robots.txtは全てのWebクローラーに対して厳密に動作するわけではありません。またWebサイトのコピーやキャッシュを行うサービスを経由すればインデックスされる可能性もあります。 そのためプライバシーに関する情報や、顧客情報など厳格な運用が必要なページに対しては、各種ユーザー認証、SSLでの暗号化など別途対策が必要になります。 またrobots.txt自体は誰にでも閲覧できる状態のため、記述する内容についても注意が必要です。 たとえば「/secret/root/id/2424」といったディレクトリがあれば「rootユーザーのIDは2424かな?」ということが推察されます。 そのような情報の内容が推察されるような記述もするべきではありません。 あくまで主要なbotに対して「できればクロールやインデックスをしないでね」と指定する程度の効果しかありません。
robots.txtのもう一つの役割
もう1つの役割が「クローラーにサイトマップの場所を知らせる」ことです。
2014年現在、Googleのシェアは97%に上ります。
参考:世界40の国と地域の検索エンジンシェアと推移【2014年6月版】
他の検索エンジンにサイトマップを登録するという行為が、労力に値する効果があるかと問われれば、疑問が残ります。
そのため代替手段として、robots.txtにサイトマップの位置を示しておくのが現実的です。
ちなみにGoogleであれば、ウェブマスターツールでサイトマップを指定するのが最も望ましい方法です。
robots.txtの記述方法
robots.txtは各社のbotによって仕様が異なります。そのため寡占状態にあるGooglebotの書式にしたがって記述します。
robots.txtの構成
robots.txtは3つのキーワードで構成されます。
| User-agent: | botの種類をユーザーエージェントで指定する |
|---|---|
| Disallow: | クロールを拒否するファイルやディレクトリのパターンを指定する |
| Allow: | クロールを許可するファイルやディレクトリのパターンを指定する |
パターンについて
各キーワードに登録するパターンは部分一致で記述します。
例えばUser-agentに「Googlebot」と書けば、「Googlebot」はもちろん「Googlebot-Image」に対しても有効になります。
また、パターンでは全ての文字列を示す「*(アスタリスク)」と、文字列の最後を示す「$(ドル)」を使うことができます。
| 対象・意味 | 記述方法 |
|---|---|
| Googlebot、Googlebot-Image等が対象 | User-agent: Googlebot |
| 全てのクローラーを対象 | User-agent: * |
| サイト全体で全てのクローラーを拒否するが、Googlebot-Imageだけは許可(後に記述した設定が有効になる) | User-agent: * Disallow: / User-agent: Googlebot-Image Allow / |
| /hoge/で始まるディレクトリを拒否 | Disallow: /hoge/ |
| /HOGE/で始まるディレクトリを拒否。(大文字小文字は区別する点に注意) | Disallow: /HOGE/ |
| hogeで始まるファイルを拒否 | Disallow: /hoge |
| /hogeで始まるディレクトリを許可するが、 /hoge/hugaで始まるディレクトリは拒否 |
Allow /hoge/ Disallow: /hoge/huga/ |
| .phpで終わるファイルを拒否。($がない場合は.phphoge等のファイルにも一致してしまう。) | Disallow: /*.php$ |
| /hoge?で始まり、任意の文字列の後、途中にuser=が入るファイルを拒否 | Disallow: /hoge?*user=* |
| サイトマップの登録 | Sitemap: http//example.com/sitemap.xml |
robots.txtのアップロード
robots.txtはサイトのルートディレクトリに保存します。
具体的にはhttp://example.com/robots.txtでアクセスできる必要があります。http://example.com/hoge/robots.txt等にアップロードしても無視されるので注意してください。
「robots.txt テスター」を利用してrobots.txtの動作をテスト
Googleのウェブマスターツールを利用していれば「robots.txt テスター」でファイルが正しく認識されているか、構文が誤っていないかを調べることができます。
まずは右下の「送信」ボタンを押して、最新のrobots.txtを送信します。送信したらブラウザを更新して、タイムスタンプと、内容を確認して下さい。
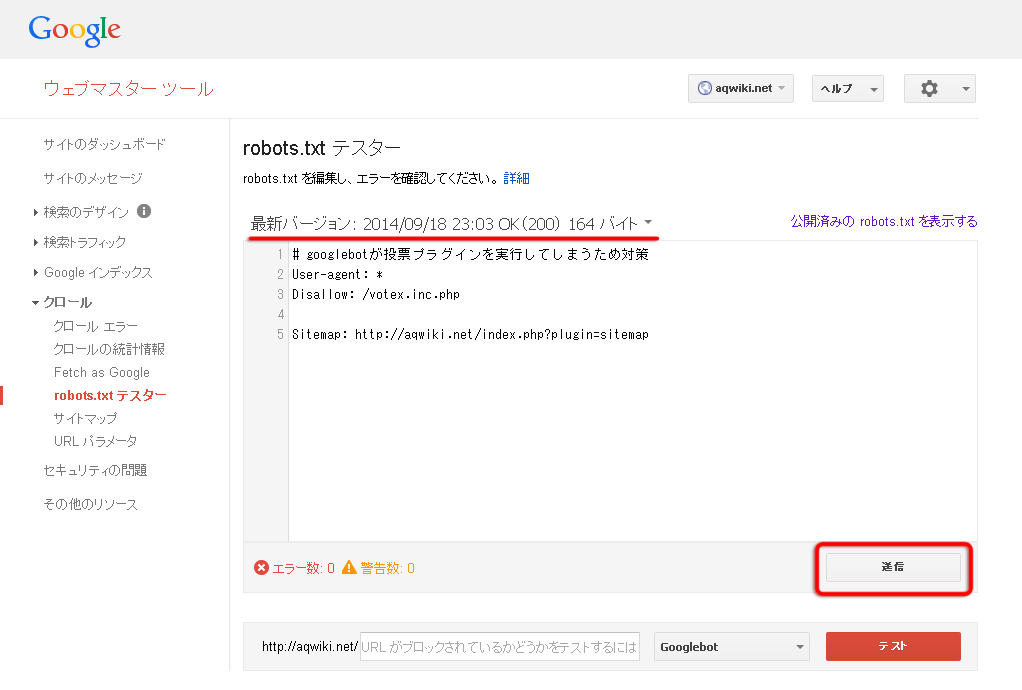
次に下にある「URL がブロックされているかどうかをテストするには、URL を入力してください」の欄にブロックしたいURLを入力し、「テスト」ボタンをクリックします。
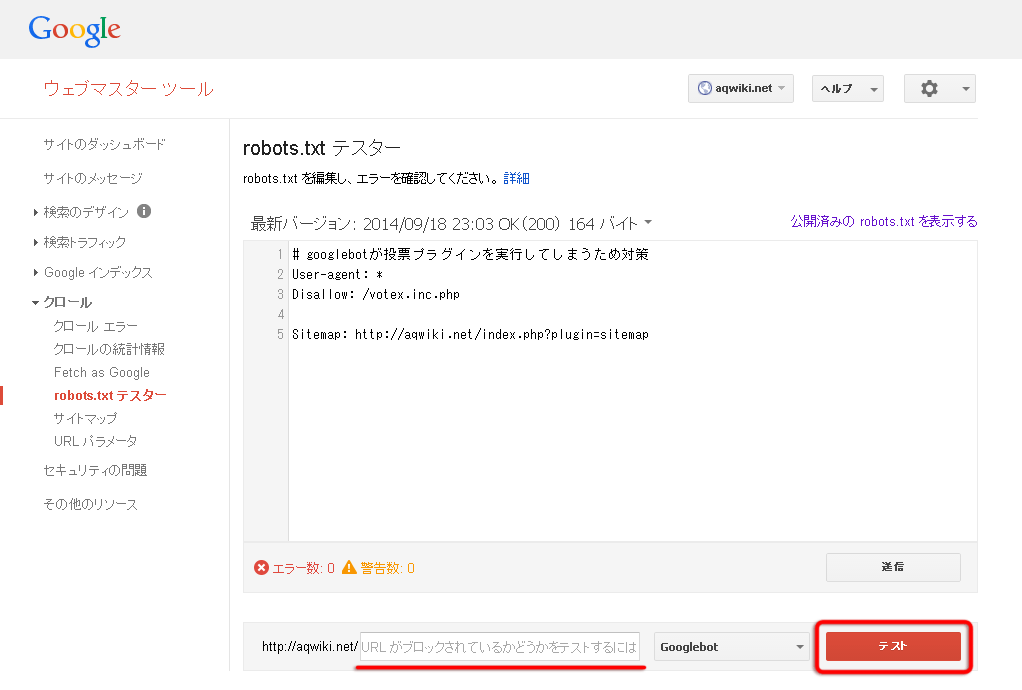
正しくブロックされていると以下のようにボタンが「ブロック済み」という表示になり、対応する設定がハイライト表示されます。
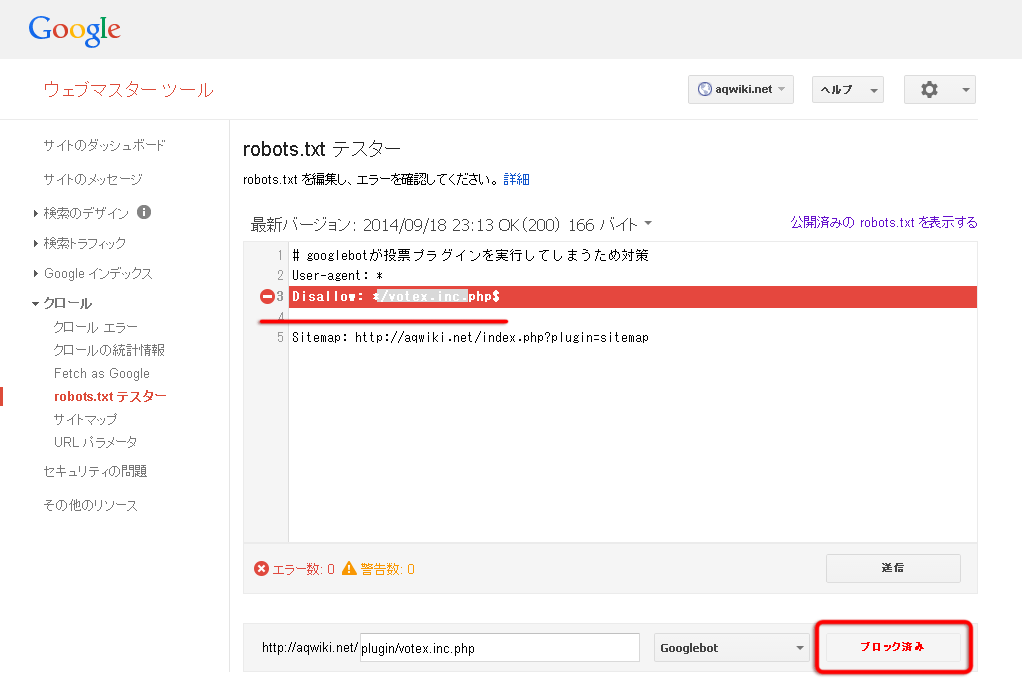
この例では「plugin/votex.inc.php」が「Disallow: */votex.inc.php$」という行の設定でブロックされていることを意味しています。
テストの結果はいかがだったでしょうか?
パターンの指定は簡単なように見えて思わぬミスが発見されたりします。実際にブロックしたいURLを使って、一度はテストすることをお勧めします。
WordPressのrobots.txtについて
「WordPressのrobots.txtは自動で作成されます」そんな記述を読んだ気がして、放置していましたが、この機会にアクセスして試したところ「404 Not Found」の表示が…。
パーマリンク設定でデフォルトの「?p=123」を選択している場合は作成されないみたいです。
ということで別のパーマリンク設定にすると作られる以下のrobots.txtを追加。
ついでにサイトマップも登録しておきました。
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Sitemap: https://oxynotes.com/?feed=rss2
構造は至って単純。ログイン時のURLである「/wp-admin/」と、WordPressのコアファイルである「/wp-includes/」以下のディレクトリはクロール拒否という設定です。
PukiWikiのrobots.txtについて
今回robots.txtの書式をまとめるきっかけになったPukiWikiの設定。
投票プラグインのvote.phpやvotex.phpは生成されたリンクにアクセスすると1つカウントするという仕様です。このリンクをGooglebotがせっせとアクセスした結果、数百・数千もの投票をしてくれました。
ものすごくありがた迷惑なので、robots.txtでアクセスを拒否しようというのが発端です。
対象のリンクは以下の様なもの
http://aqwiki.net/?cmd=votex&pcmd=inline&refer=%E3%82%A2%E3%82%AF%E3%82%A2%E3%82%B7%E3%83%A7%E3%83%83%E3%83%97DINO&digest=0f41d5a5eec9a5c344e0843b84e563da&vote_id=0&choice_id=0
このURLに対応するパターンは以下のようにしました。
Disallow: */*cmd=votex*
テストツールで無事にブロックできていることを確認して、全体としては以下のように作成。
# googlebotが投票プラグインを実行してしまうため対策 User-agent: * Disallow: */*cmd=votex Disallow: */*RecentChanges Disallow: */*RecentDeleted Sitemap: http://aqwiki.net/index.php?plugin=sitemap
以上、robots.txtのまとめでした。
記述方法やテストツールの結果など、意外な発見があったのではないでしょうか?
試しに大手のrobots.txtにアクセスしてみて参考にしてみてください。
Googleのrobots.txt
Yahoo!のrobots.txt(yahooトップページには無し)
WordPress公式のrobots.txt
 迷惑ボットMJ12bot/v1.4.5によるクロールをrobot.txtで停止する方法
迷惑ボットMJ12bot/v1.4.5によるクロールをrobot.txtで停止する方法 検索エンジンに自分のサイトを登録
検索エンジンに自分のサイトを登録 Apacheで拡張子が「.html」のファイル内でPHPを実行する方法
Apacheで拡張子が「.html」のファイル内でPHPを実行する方法 ads.txtの設置方法を通して学ぶインターネット広告の問題点
ads.txtの設置方法を通して学ぶインターネット広告の問題点 URLを正規化して、Googleにページの重要度を伝える方法
URLを正規化して、Googleにページの重要度を伝える方法 文字だけでフォルダのツリー構造や表を作成する方法
文字だけでフォルダのツリー構造や表を作成する方法