このサイトはGMO VPSを利用して運営されています。OSはCent OS 6です。
サーバの状況を把握するためにdstatコマンドを利用し、norikuraで抽出し、GrowthForecastでグラフ化しています。
何かしらの異常が発生し、特定の項目がしきい値を越えるとメールで通知するように設定しています。
(この方法はこちらのページで解説しています。)
今回は通知があったわけでもなく、特に動作が遅くなったというわけでもなかったのですが、何気なくグラフを見ていたところCPUのusrが異常に上がっていることに気が付きました。
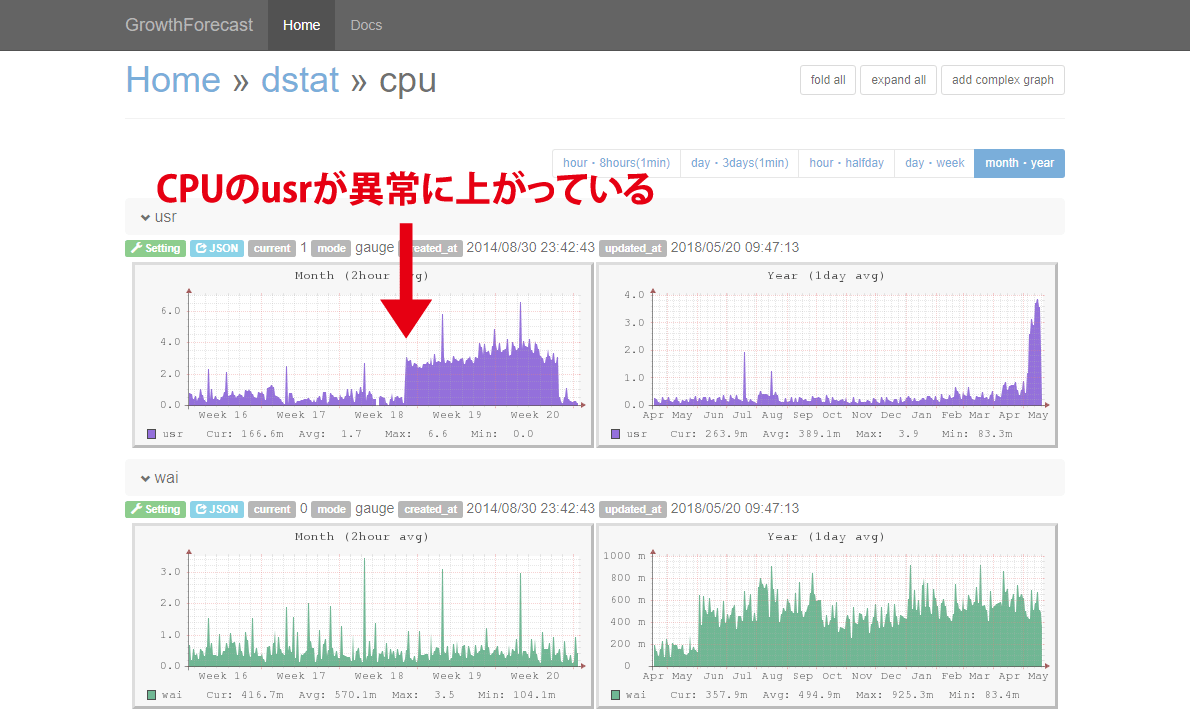
異常といっても4%程度なので、アラートは作動しません。(後に収束しているのは対策をしたため)
しかし通常時は1%にも満たないのに、急に増加しているのは気になります。
そこでtopコマンドで原因となっているプロセスを調べます。
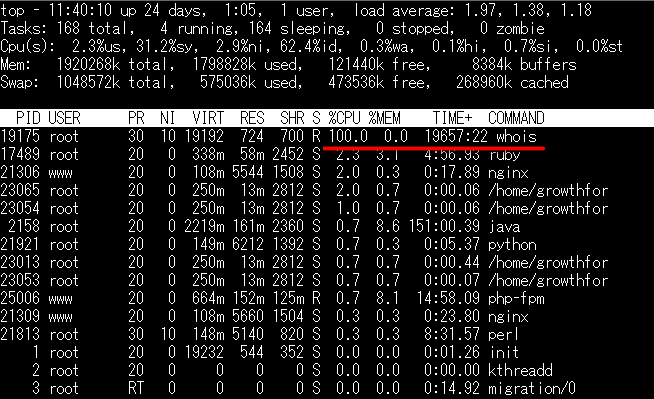
なぜかwhoisのCPU利用率が100%になっています。
通常であればアラート案件ですが、GMO VPSのCPUがマルチスレッドで高性能のため、1つのプロセスが100%に張り付いても顕在化しなかったようです。
こうして見返してみると、load acerageの値が1~2と高いようです(通常時は0.1もいかない)。load acerageの監視・通知なども併用したほうが良さそうです。
何はともあれ、とりあえず原因を調べるべくwhoisを利用しているプロセスを調べます。
# ps -ef | grep whois root 19175 19172 99 May04 ? 13-15:40:27 whois 196.196.220.10
196.196.220.10を調べると、普通にwhoisサーバなので、whoisを利用した問い合わせが暴走の原因のようです。
whoisの問い合わせがサーバの動作に致命的な影響を与えるとは考えられないので、プロセスIDを指定して殺します(これ、怖い表現ですよねw)。
# kill -9 19175
これで無事にサーバは落ち着きました。
その後数日経過を見ていますが、ひとまずこれで問題ないようです。
検索すると同様な報告の多くはfail2banで使うwhoisが原因とのこと。
どのページに記載されている内容も似たり寄ったりで、このような現象はfail2banを数年使い続けて1度あるかないかなので、無視しても構わないが、気になるなら問い合わせを無視するために設定ファイルを変更すると良いとのこと。
私の場合はSwatchでサーバログを利用し、アクセス規制や通知を行っているのですが、その際にwhoisコマンドを利用しています。
更に詳しく調べると、whoisで利用されるjwhoisというクライアントのバグとのこと。
FedoraとRHEL 7系では対策されていますが、RHEL 6では放置されているとのこと。当然Cent OS 6系でも放置されています。
このサーバはCent OS 6で運営されており、Swatchによるセキュリティ対策を行ったのは4年前です。
その間、一度もこのような自体になっておらず、サーバへの負担も限定的であることから、特に対策はしないことにしました。
代わりにload acerageがしきい値を超えた場合に通知が来るようにして、適宜対応したいと思います。
 サーバのログを監視するSwatchの導入方法と使い方を解説
サーバのログを監視するSwatchの導入方法と使い方を解説 手軽にデータをグラフ化するGrowthForecastのインストールと使い方
手軽にデータをグラフ化するGrowthForecastのインストールと使い方 fluentdのFilter Pluginsを使ってイベントを自在に操る方法
fluentdのFilter Pluginsを使ってイベントを自在に操る方法 Swatchでログを監視して、攻撃に合わせた対策を自動で実行する方法
Swatchでログを監視して、攻撃に合わせた対策を自動で実行する方法 CentOS5.9のMySQLを5.6.14にアップデートする方法
CentOS5.9のMySQLを5.6.14にアップデートする方法 サーバリソースをリアルタイムに監視するdstatのインストールと使い方
サーバリソースをリアルタイムに監視するdstatのインストールと使い方 /etc/cron.daily/logrotateでunexpected textエラーが発生した際の対処法
/etc/cron.daily/logrotateでunexpected textエラーが発生した際の対処法