当ブログでは過去に「fluentdとGrowthForecastを利用してグラフを書き出す方法」を紹介させていただきました。
メンテナンスといえばfluentdをアップデートした程度で何年も変わらず動作していたのですが、今回サーバのアップデートを行ったところ、グラフの書き出しが停止してしまいました。
プロセスを見るべく以下のコマンドを打ちますがtd-agentが起動していません。
# ps ax | grep td-agent
原因を探るべくtd-agentのログを確認します。
# vi /etc/td-agent/td-agent.conf
…なにやらエラーがズラッと表示されています。
ということで、fluentdのアップデートに合わせて設定を見直しました。その際に利用したFilter Pluginsという機能がものすごく便利だったので、共有したいと思いこのページにまとめました。
fluentdとtd-agentの関係性について
さて、早速解説を…と行きたいところですが、fluentdとtd-agentの関係性について誤解されている方が多いので補足させていただきます。
よくある間違いが「td-agentをfluentdのCent OS版と勘違いしているパターン」です。
2つの違いはfluentdの公式ドキュメントにも書いてあります。
曰く「FlentdではC言語やRubyを利用しており、導入や管理の敷居が高いため、rpmパッケージでFlentdの安定版を提供しています」とのこと。
つまり、td-agentはfluentdだけでなく、動作に必要な依存関係にあるソフトや管理コマンドなども含めたパッケージの総称です。
具体的には以下のコンポーネントが含まれています。
ruby(1.9.3-p194):http ://www.ruby-lang.org/en/ jemalloc:http : //www.canonware.com/jemalloc/ fluentd:https : //github.com/fluent/fluentd fluent-plugin-mongo:https : //github.com/fluent/fluent-plugin-mongo fluent-plugin-webhdfs:https : //github.com/fluent/fluent-plugin-webhdfs fluent-plugin-s3:https : //github.com/fluent/fluent-plugin-s3 fluent-plugin-scribe:https : //github.com/fluent/fluent-plugin-scribe fluent-plugin-flume:https : //github.com/fluent/fluent-plugin-flume fluent-plugin-td:https : //github.com/treasure-data/fluent-plugin-td
またyumでインストールを行うと依存関係にあるパッケージとして以下もインストールされます。
openssl、readline、libxslt、libxml2 td-libyaml(rpm)またはlibyaml(deb)
このように、fluentdの動作に必要な環境をyumだけで整えてくれるのがtd-agentです。XamppとApacheみたいな関係ですね(わかりにくいか…)。
ということでtd-agentとfluentdは別のものなのでバージョンは一致していません。詳しくは公式のChangeLogをご覧ください。
ChangeLogにある通り2020年2月現在の最新版であるtd-agentのv3.5.1にはfluentd v1.7.4が含まれています。
この辺をごっちゃにして質問されてもお互いにチンプンカンプンになるだけです。
当然ですがrbenvなどを利用すれば、自分の好きなバージョンのrubyとfluentdを導入することもできます。
この場合のプラグインのインストール方法は以下のようにgem(もしくはfluent-gem)を使います。
# gem install fluent-plugin-growthforecast
これがtd-agentを利用してインストールしたfluentdにプラグインを追加する場合は以下のようにtd-agent-gemを使います。
# td-agent-gem install fluent-plugin-growthforecast
このように管理コマンドにも違いがあるので注意してください。
以上、長くなりましたがtd-agentで作業する上での注意点でした。
fluentdをアップデートした際に発生したエラーと対処法
ではtd-agentの設定に戻ります。
プラグインの指定方法に関するエラー
まずは以下のログから。
[warn]: 'type' is deprecated parameter name. use '@type' instead.
公式ドキュメントによると、いつからかプラグインの指定方法が「type」から「@type」へ変更になったようです。
設定ファイルのtypeに全て@を追加します。
<source> type http </source>
以下のように変更。
<source> @type http </source>
mapプラグインに関するエラー
さらに別のエラーも続きます。
[error]: config error file="/etc/td-agent/td-agent.conf" error_class=Fluent::ConfigError error="Unknown output plugin 'map'. Run 'gem search -rd fluent-plugin' to find plugins"
なにやらmapプラグインが見つからないとのこと…。以前入れた覚えがあるのにおかしいなと思いつつインストールします。
# td-agent-gem install fluent-plugin-map
再び起動してみますがまた別のエラーが出ました。
2019-12-06 12:26:53 +0900 [warn]: out_map is now deprecated. It will be removed in a future release. Please consider to use filter_map.
どうやらmapプラグインが非推奨になったとのこと。GrowthForecastへの出力も正しく行われていません。
代わりにfilter_mapを利用すべしとのことなので調べてみます。
元々のmapプラグインを利用していた際の設定は以下の通りです。
# dstatからイベントログを取得
<source>
type dstat
tag dstat
option -cdnm --tcp --udp # dstat実行時のオプション(グラフ化するデータ)を指定
delay 10
</source>
# GrowthForecast用にメッセージを加工する
<match dstat>
type copy
# CPU関連の結果だけを取り出す
<store>
type map
tag "perf.cpu"
time time
record record['dstat']['total cpu usage']
</store>
# ディスクIO関連の結果だけを取り出す
<store>
type map
tag "perf.dsk"
time time
record record['dstat']['dsk/total']
</store>
# メモリ関連の結果だけを取り出す
<store>
type map
tag "perf.mem"
time time
record record['dstat']['memory usage']
</store>
# ネット関連の結果を抜き出す
<store>
type map
tag "perf.tcp-sockets"
time time
record record['dstat']['tcp sockets']
</store>
# 通信量関連の結果を抜き出す
<store>
type map
tag "perf.network"
time time
record record['dstat']['net/total']
</store>
<store>
type map
tag "perf.udp"
time time
record record['dstat']['udp']
</store>
</match>
# GrowthForecastに転送する(ローカル用)
<match perf.**>
type growthforecast
gfapi_url http://127.0.0.1:5125/api/
service dstat
tag_for section
remove_prefix perf
name_key_pattern .*
</match>
dstatの出力をGrowthForecastへ渡すための設定です。
入力プラグインでdstatを利用していますが、このプラグインでは上記の設定で以下のように出力されます。
2019-12-17T17:55:57+09:00 dstat {"hostname":"example.com","dstat":{"total_cpu_usage":{"usr":"1.193","sys":"0.136","idl":"96.285","wai":"2.181","hiq":"0.068","siq":"0.136"},"dsk/total":{"read":"2216755.200","writ":"32768.0"},"net/total":{"recv":"12249.100","send":"76632.700"},"memory_usage":{"used":"1711374336.0","buff":"28848128.0","cach":"280616960.0","free":"80556032.0"},"tcp_sockets":{"lis":"23.0","act":"23.0","syn":"1.0","tim":"42.0","clo":"14.0"},"udp":{"lis":"8.0","act":"0.0"}}}
dstatの項目の中にtotal_cpu_usageがあり、さらにその中にusrやsysといった値がネストされています。
GrowthForecastへデータを渡すには項目名と値のセットにする必要があります。プラグインからの出力をそのままtagでマッチさせて「name_key_pattern .*」としても目的の値は取れません。
そこでmapプラグインを利用してperf.cpuというタグにrecord[‘dstat’][‘total cpu usage’]の値を入れて出力を変更していました。
この作業をfilter_mapに置き換えろとのこと。「filter_map」とは何じゃラホイとFluentd公式のドキュメントを見てみます。(いつの間にかものすごく見やすい公式ドキュメントができてました)
すると「Filter Plugins」なるものを発見。
ななめ読みしてみると入力プラグインのデータを変更するためのプラグインらしい。
公式の解説がものすごく丁寧に詳しく書いてあるので、このページでは今回の設定に必要な部分のみ解説します。
「Filter Plugins」は入力プラグインで取得したデータを変更するたものです。レコードの値を加工したり、追加や削除をする際にも利用します。公式でサポートされているため導入の手間がかかりません。
基本的にはディレクティブ扱いなので、sourceやmatchと同じように記述します。私は当初mapプラグインと同じように使えるのかと思い、matchディレクティブ内で使いましたが、もちろんそれでは動作しません。
簡単に流れを見ると以下のようになります。
※Flentdのイベントについて
Filter Pluginsでイベントを変更するにあたって、まずはFlentdのイベントについて仕様を理解する必要があります。
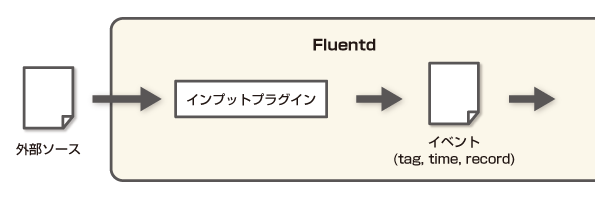
Flentdで解析する対象がデータソースです。このソースを入力プラグインを利用してFlentdイベントに加工します。

Flentdイベントはtag、time、recordの3つで構成されています。
tagは一致するイベントをキャッチするためのもの。
timeはそのままソースから取得した時間です。
recordはjson形式でkeyとvalueを持ちます。keyとvalueのセットでfield(フィールド)とも呼ばれます。「レコードに新しいフィールドを追加する」という場合、recordにJSON形式で新しいkeyとvalueを追加することを指します。
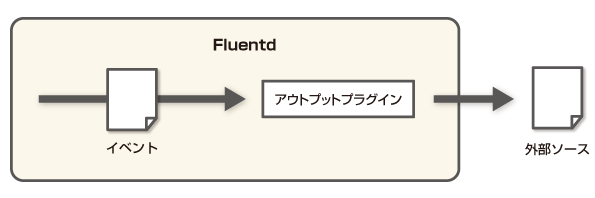
通常はイベントをアウトプットプラグインに渡して外部へ出力します。
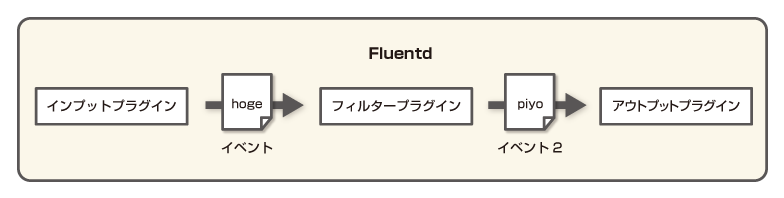
今回解説するフィルタープラグインはインプットとアウトプットの間に挟んでイベントを変更する際に利用します。
fluentdのFilter Pluginsの使い方
まずはFilter Pluginsの設定方法を見ていきます。
# 入力プラグインのhogeでタグにhugaを付ける
<source>
@type hoge
tag huga
</source>
# filterプラグインで新しいレコードを追加
<filter huga>
@type record_transformer
<record>
new_field "value2"
</record>
</filter>
# 出力用のプラグインに渡す
<match huga>
@type stdout
</match>
まずわかりやすくするためにsourceディレクティブでhogeというインプットプラグインで値を取得し、hugaというtagを付けています。
このときの入力を便宜上、以下のようにします。
huga: {"field1":"value"}
8行目のFilterディレクティブでhugaタブをキャッチしてrecord_transformerプラグインで値を変換しています。
10行目のrecordディレクティブで新しいフィールドnew_fieldとvalue2を追加。
具体的には以下のように新しいフィールドが追加されます。
huga: {"field1":"value", "new_field":"value2"}
このようにFilter Pluginsを利用するとインプットプラグインから渡されたイベントを簡単に変更することができます。
と、ここまでなら今までにも有志による似たプラグインも存在しました。今回使えなくなって困ったmapプラグインや桁数を操作するampプラグインなどです。
record_transformerプラグインのありがたいところは簡単なrubyの構文が使えることです。
公式の解説にあるのは以下のものです。
<filter huga>
@type record_transformer
enable_ruby
<record>
avg ${record["total"] / record["count"]}
</record>
</filter>
record_transformerプラグインで、enable_rubyというパラメータを追加すると${}のカッコの中でrubyの構文が使えます。この例では「totalフィールドの値」割る「countフィールドの値」をavgというフィールドに渡しています。
totalが10、countが5の場合、具体的には以下のような出力になります。
huga: {"total":"10", "count":"5", "avg":"2"}
また、今回のdstatのようにネストした項目は以下のように[]で繋げると値が取れます。
record["dstat"]["total_cpu_usage"]
簡単な計算だけでなくrubyと同じようにgsubで正規表現を利用した置き換えなども可能です。これらの機能を利用すれば、セキュリティの関係で出力したくない情報を削除したり、特殊な条件だけ出力するといった、従来であれば複数のプラグインを組み合わせなければならなかった場合にも対処が可能です。さらに詳しく知りたい方は、Filter Pluginsの解説をご覧ください。
では上で示したdstatプラグインとmapプラグインを利用した方法から、今回のFilter pluginsを利用した方法に置き換えてみます。
<match dstat>としていた部分を以下のようにFilterディレクティブに置き換えます。
<filter dstat>
@type record_transformer
renew_record # レコードを追加ではなく着信データを新規に作り直す
enable_ruby # ${}でレコードを取得するにはrubyを有効にする必要あり
<record>
01_total_cpu_usage:usr ${record["dstat"]["total_cpu_usage"]["usr"]}
02_total_cpu_usage:sys ${record["dstat"]["total_cpu_usage"]["sys"]}
03_total_cpu_usage:idl ${record["dstat"]["total_cpu_usage"]["idl"]}
04_total_cpu_usage:wai ${record["dstat"]["total_cpu_usage"]["wai"]}
05_total_cpu_usage:hiq ${record["dstat"]["total_cpu_usage"]["hiq"]}
06_total_cpu_usage:siq ${record["dstat"]["total_cpu_usage"]["siq"]}
07_dsk_total:read ${record["dstat"]["dsk/total"]["read"]}
08_dsk_total:writ ${record["dstat"]["dsk/total"]["writ"]}
09_net_total:recv ${record["dstat"]["net/total"]["recv"]}
10_net_total:send ${record["dstat"]["net/total"]["send"]}
11_memory_usage:used ${record["dstat"]["memory_usage"]["used"]}
12_memory_usage:buff ${record["dstat"]["memory_usage"]["buff"]}
13_memory_usage:cach ${record["dstat"]["memory_usage"]["cach"]}
14_memory_usage:free ${record["dstat"]["memory_usage"]["free"]}
15_tcp_sockets:lis ${record["dstat"]["tcp_sockets"]["lis"]}
16_tcp_sockets:act ${record["dstat"]["tcp_sockets"]["act"]}
17_tcp_sockets:syn ${record["dstat"]["tcp_sockets"]["syn"]}
18_tcp_sockets:tim ${record["dstat"]["tcp_sockets"]["tim"]}
19_tcp_sockets:clo ${record["dstat"]["tcp_sockets"]["clo"]}
20_udp:lis ${record["dstat"]["udp"]["lis"]}
21_udp:act ${record["dstat"]["udp"]["act"]}
</record>
</filter>
オプションにrenew_recordとenable_rubyを指定しています。
renew_recordは古いレコードを廃棄して、新しく指定したrecordだけを生かす方法です。このオプションを追記しないとdstatプラグインから渡された既存の出力も残ります。今回はGrowthForecastに渡すだけなので既存の出力は必要無いため削除しています。
enable_rubyは上で解説したとおりです。
フィールド名に連番が振られています。これはGrowthForecastでの表示順を指定するためのものです。GrowthForecastはデフォルトだと名前順に項目が並ぶので見やすいように連番を振りました。
この設定で出力を行うと以下のようなグラフとして出力されます。
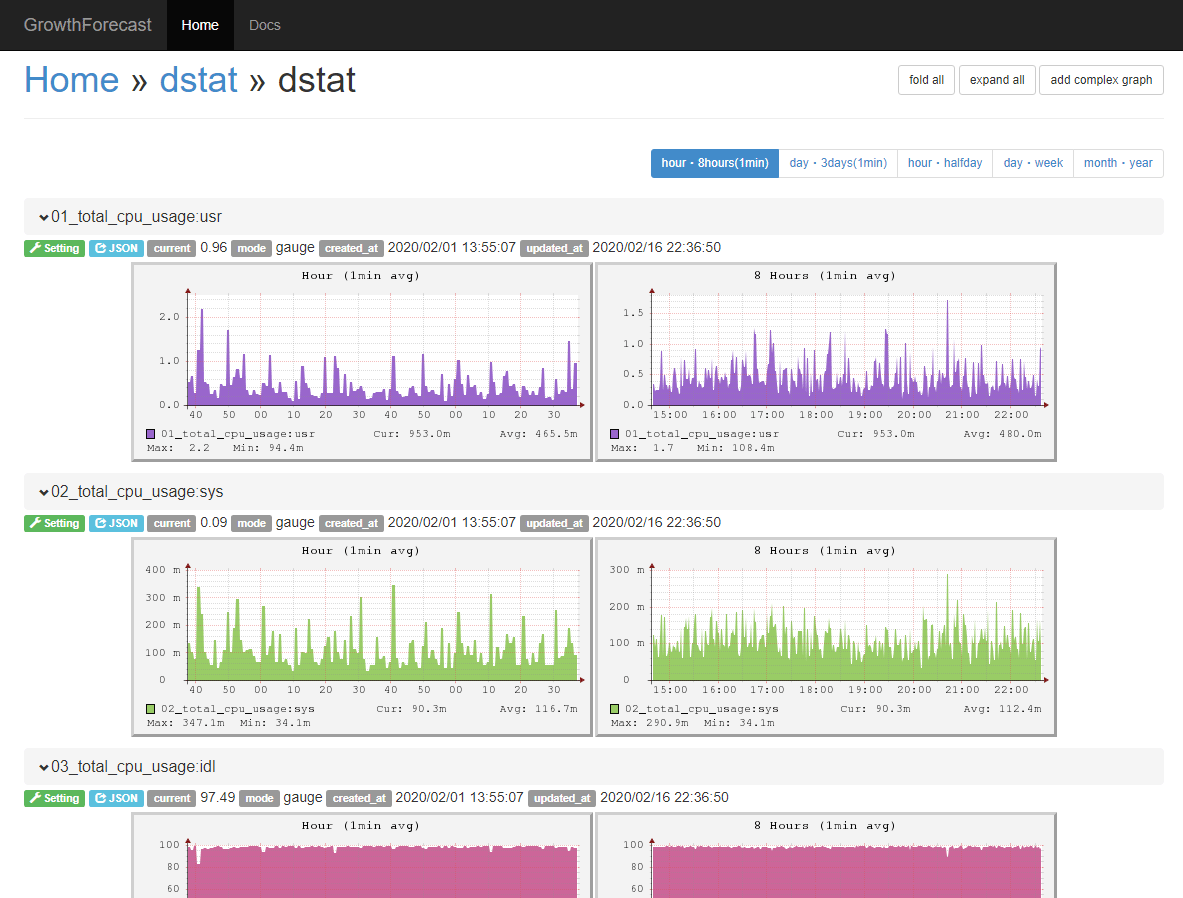
無事にネストしたフィールドの値も取得できて、連番通りにグラフも並んでいます。
mapプラグインを利用したときはtotal_cpu_usageやdsk_totalといったコマンドごとにページを分けていましたが、一覧性が悪いので今回は1ページにまとめました。
以前と同じように複数ページに分けたい場合はfluent-plugin-routeというプラグインが用意されています。解説ページを見れば迷いようが無いくらいわかりやすく書いてあるので詳しく知りたい方はfluent-plugin-routeの公式ページをご覧ください。
以上、Filter Pluginsを使ってイベントを操作し、目的のOutput pluginへデータを渡す方法を解説しました。
Filter Pluginsには今回解説したrecord_transformerプラグインだけでなく、他にも有用なプラグインが用意されています。
grepは特定のレコードを削除する際に便利ですし、stdoutを使えばデバッグ作業がはかどります。
紹介したとおり簡単な記述でログを操作できるのもFluentdの特徴であるjson形式の恩恵です。
というより、もはやソフトのログにfluentd形式というのを標準のログシステムとして搭載してほしいくらいです。
 td-agent2へアップデートする方法と、Dstat pluginが動作しない場合の対処法
td-agent2へアップデートする方法と、Dstat pluginが動作しない場合の対処法 ビックデータ時代のログ収集管理ツールFluentdのインストールと使い方
ビックデータ時代のログ収集管理ツールFluentdのインストールと使い方 fluentdとNorikraでDoS攻撃を遮断し、メールで通知する方法
fluentdとNorikraでDoS攻撃を遮断し、メールで通知する方法 手軽にデータをグラフ化するGrowthForecastのインストールと使い方
手軽にデータをグラフ化するGrowthForecastのインストールと使い方 WordPressプラグインを公式プラグインディレクトリへ追加する方法
WordPressプラグインを公式プラグインディレクトリへ追加する方法 fluentdと連動して集計処理を行うNorikraの導入方法
fluentdと連動して集計処理を行うNorikraの導入方法 迷惑ボットMJ12bot/v1.4.5によるクロールをrobot.txtで停止する方法
迷惑ボットMJ12bot/v1.4.5によるクロールをrobot.txtで停止する方法