初めてEPL文に触れる人には敷居の高いNorikra

「NorikraのクエリはSQLライクなのでカジュアルに追加しよう」と、いかにも簡単そうに言われても文法がわからなければ書きようがありません。
早速公式の「Query of Norikraページ」を見てみます。
「全部英語で表現も専門的でさっぱりわからない…」
と、私のように初めて学ぶことが英語のドキュメントだと理解するのが大変という方も多いと思うので、私なりに解説ページを解説します。
公式ドキュメントをすらすらと理解できる方は素直に「公式のドキュメント」を参照してください。
目次
- NorikraのQueryとは何か
- Queryは具体的に何をするもの?
- Queryの名前
- Queryの構文
- ターゲット名(target name)
- フィールド名(field name)とエンティティ
- ビュー(View)について
- Field name escape
- Container fields
- Java methods, operators and functions
- Group by, Having, Order by, Limit
- Fully-qualified field names and container fields
- Filters/Patterns
- その他のルール
NorikraのQueryとは何か
NorikraのQueryはEsper’s EPL(エスパーズ イーピーエル)を踏襲しています。
EsperとはJavaで書かれたCEP(Complex Event Processing:複合イベント処理)のためのコンポーネントです。要はリアルタイムにイベントを処理するためのソフトです。
ではEsper’s EPLとは何かというと、EPL(Event Processing Language)の略で、Esperで使うイベントを操作するための言語です。このEPL文がSQL文と似ているためSQLライクと言われるわけです。
まとめると「イベント駆動型アプリケーションで利用されるEPL文 = NorikraのQuery」となります。
Esperについて詳しく調べたいという方は「Esper Reference」を参照してください(気軽に参照できるような文章量ではないですがw)。
また「こちらのページ」でQueryとイベントをテストできます。
Esper’s EPLと全く同じものというわけではなく、幾つかの相違点があります。
ただ、この投稿を読んでいる方にとってはEsper’s EPL自体が耳慣れないものだと思うので、相違点をあげるよりも、以下の書式を見てもらったほうが理解が早いと思います。
Queryは具体的に何をするもの?
Queryは入力イベントを選別したり、集計する条件を指定するためのものです。
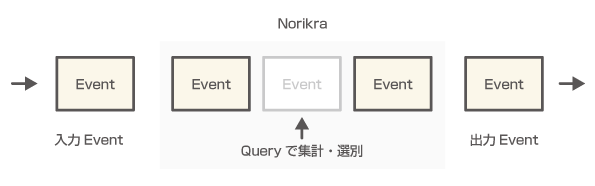
ageが15以上のものだけ出力する。Aが出現した回数をカウントして出力する。といった具合です。
Queryの名前
全てのQueryは名前(name)と、グループ名(group)を持ちます。
nameは必須で一意である必要があり、groupは空白でもOKです(空白の場合はグループ名はdefaultになります)。
Queryの構文
EPL文はSQL文と同じように大文字小文字を区別しません。
しかしターゲット(target)名と、フィールド(field)名は区別します。
簡単なQueryのサンプル
SELECT age FROM accesses.win:time_batch(1 hours) GROUP BY age
accessesというターゲットから、ageというフィールドを取得し、ageでグループ化しています。
普段SQL文に親しんでいる方ならわかるとおり、SELECTやFROM、GROUPといった書式は共通です。
また、ターゲットはテーブル、フィールドはカラムに相当します。
(win:time_batchなどは後述)
ターゲット名(target name)
ターゲットとは上の例の通り、RDBMSのテーブル名のようなものです。
使える文字は [a-zA-Z][_a-zA-Z0-9]* となっています。
つまり大文字小文字のアルファベットで始まり、続く文字は前出の文字に加え、アンダーバーと数字です。
ちなみにfluentdでターゲット名を指定するにはfluent-plugin-norikraのtarget_stringで指定します。
フィールド名(field name)とエンティティ
こちらはRDBMSのカラム名のようなものです。
fluentdから渡されるデータを例にすれば、JSON形式に変換されたlogのkeyの項目です。
例えばfluentdでdstatでサーバの使用状況を取得していたとします。
fluentdで扱うJSONは以下のようになっています。
2015-12-15T00:00:06+09:00 dstat {
"dstat":{
"total_cpu_usage":{
"usr":"2.006","sys":"0.519"
},
"dsk/total":{
"read":"2015232.0","writ":"163020.800"
}
}
}
fluent-plugin-norikraでnorikraに渡すと以下の様なデータになります。(ターゲット名にdstatを指定した例)
{
"name":"dstat",
"fields": {
"total_cpu_usage": {
"usr":"2.006","sys":"0.519"
},
"dsk/total": {
"read":"2015232.0","writ":"163020.800"
}
},
}
この例で言う、nameのdstatがターゲット名。fieldsのtotal_cpu_usageやdsk/totalがフィールド名です。
フィールド名はJSON形式のkeyでサポートされているものは何でも扱えますが、Queryで記述する際はスペース( )やドット(.)はEPL文で特別な意味を持つので使えません。
それらの文字はアンダースコア(_)で置換します。
ビュー(View)について
Queryの構文の解説で「win:time_batch(1 hours)」という見慣れないコードがありました。
これがViewと呼ばれるもので集計するデータに条件を追加するためのものです。
書式は以下のようになります。
namespace:name(view_parameters)
win:time_batch(1 hours)の例で言えば、winが名前空間、time_batchがViewの名前、1 hoursがViewパラメータです。
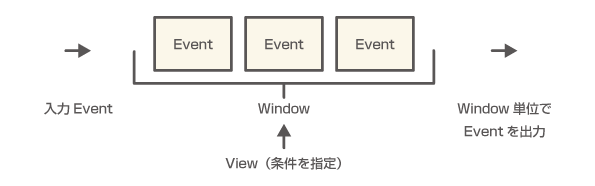
winはWindowの略で、1度に扱うデータの単位を指します。出荷するコンテナの規格みたいなものですね。
Queryの動作確認
書式を見るだけでは、なかなか理解できないという方も多いのではないでしょうか。
Norikraにはそんな方にお勧めの機能があります。コマンドでイベントを流して動作を確認することができます。
まずnorikraのページ(前回の解説の通りならhttp://<自分のIPアドレス>:26578/)にアクセスします。
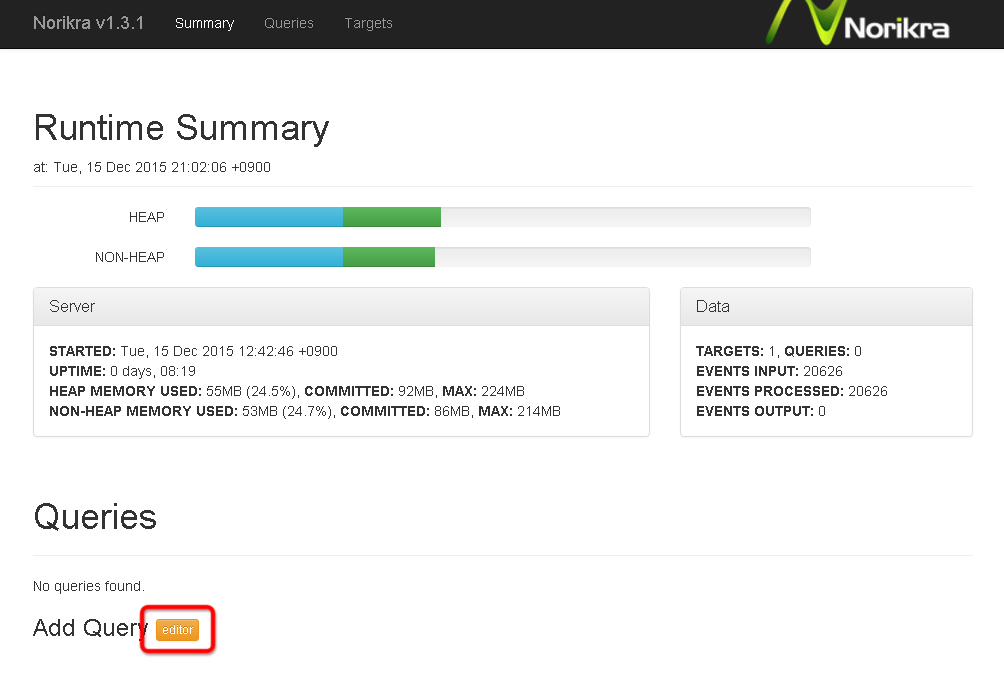
「Add Query」の「Editor」ボタンをクリックし、「Query」に以下のクエリを入力してください。
これはターゲット「test」のフィールド「name」を60秒間隔で取得するというクエリです。
SELECT name FROM test.win:time_batch(60 sec)
Query Nameは必須なので「test」とします。Groupはブランクで構いません。
入力したら「Add Query」ボタンで確定します。
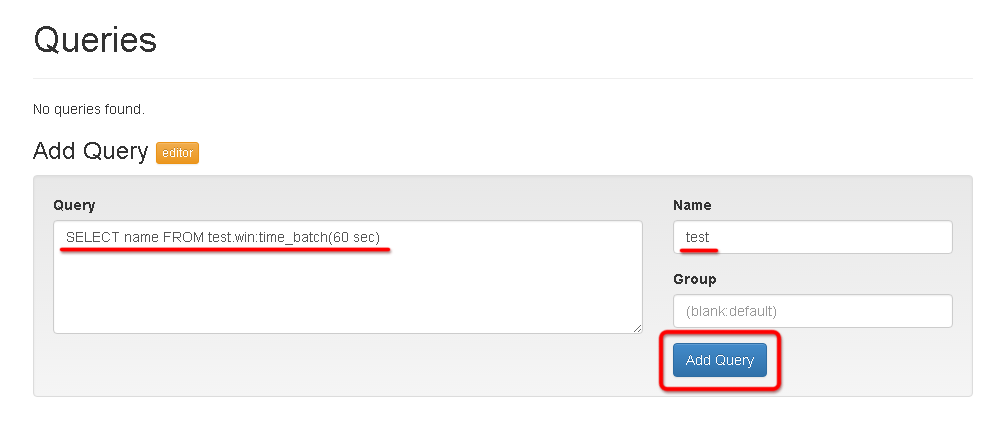
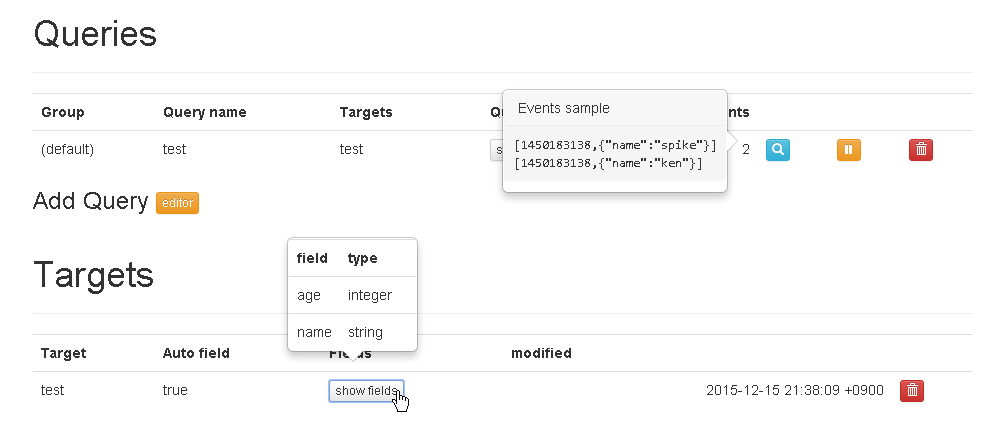
するとQueriesとTargetsに項目が追加されます。
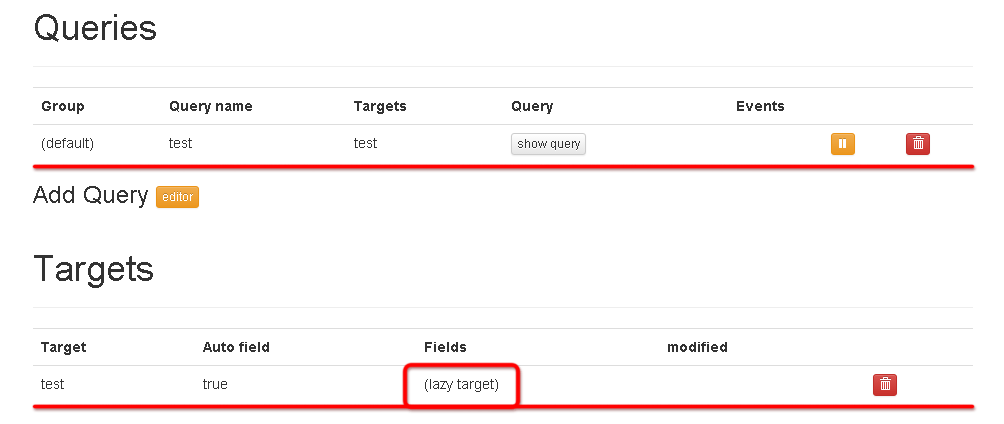
このようにQueryを登録すると、対応するTargetが自動で追加されます。
TargetのAuto fieldがtrueになっていますが、有効だと実際に入力イベントを流した際にfieldの型が自動で判別されます。今のところ何もイベントが無いので「lazy target」となっています。
ではコマンドでイベントを流します。(イベントは流した後、数秒停止します。順番に打ってください)
# cd ~/norikra ← /root/norikraに入れたためディレクトリを移動 # echo '{"name":"spike", "age":27}' | norikra-client event send test # echo '{"name":"ken", "age":27}' | norikra-client event send test
time_batchで60秒を指定したので、60秒ほど待ってNorikraのページを更新します。
すると以下のようにEventsに虫眼鏡のマークが表示されます。

クリックすると処理したイベントの内容が表示されます。イベントの先頭の数値はイベントが出力されたUNIX時間です。
またTargetsのfieldの項目も自動で型が表示されます。
このように慣れないうちは自分の追加したQueryが想定したイベントで正しく処理されるか確認することをお勧めします。
このページでは可能な限りテストクエリとテストイベントという形で紹介します。もし良かったらご自身でも試してみてください。
ビュー(View)を指定しない場合
Viewを指定しないQueryは全てのイベントを即座に出力します。
大量のイベントを処理する場合、相応のメモリを消費するので注意が必要です。
テストクエリ)ageが15以上の場合、全てのイベントを出力する
SELECT name, age FROM test WHERE age > 15
テストイベント(1つ1つコマンドを打つのが面倒なので以降まとめます)
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \ echo '{"name":"jane", "age":20}' | norikra-client event send test && \ echo '{"name":"ken", "age":12}' | norikra-client event send test
出力イベント
[1450185487,{"age":27,"name":"spike"}]
[1450185495,{"age":20,"name":"jane"}]
タイムスタンプを見ると最初のイベントが実行されてから8秒後にふたつ目のイベントが実行されています。時間を指定してないので即イベントが出力されています。
また、ageが12のkenの項目は除外されています。「WHERE age > 15」が正しく動作していることがわかります。
タイムウィンドウ(Time window)
一定の時間経過した時点でイベントを実行します。いわゆる指定した時間だけ入力したイベントをバッファしてまとめて処理します。
書式
win:time_batch( time-period )
time-periodの第1引数
第1引数は時間を指定します。使える単位は以下のとおり。
sec|second|seconds, min|minute|minutes, hour|hours, day|days to year|years
EPL文では以下のように組み合わせて使用します。(millisecondsは使えるか不明)
10 seconds 10 minutes 30 seconds 20 sec 100 msec 1 day 2 hours 20 minutes 15 seconds 110 milliseconds 0.5 minutes 1 year 1 year 1 month
time-periodの第2引数
第2引数には基準となる時間からのオフセット時間を指定します。
まず第2引数に「<num>L」と数値を指定するとunix epoch(UNIX時間)を基準として、第1引数の値で割り切れる時間でイベントを区切ります。
例えば第2引数を指定しないで「win:time_batch(10 sec)」とした場合、最初のイベントを取得した時点を基準として10秒毎にイベントを処理します。
{"time":"2015/12/10 13:58:46","count":0}
{"time":"2015/12/10 13:58:56","count":1}
対して第2引数に0Lを指定して「win:time_batch(10 sec, 0L)」とした場合は以下のように、ピッタリ10秒単位でイベントを処理します。
{"time":"2015/12/10 13:58:40","count":0}
{"time":"2015/12/10 13:58:50","count":1}
第1引数で「1 min」第2引数で「0L」とすればピッタリ1分単位。第1引数を1hourとすればピッタリ1時間単位で処理されます。
さらにミリ秒単位で数値を指定すると、その時間の分だけずらして処理されます。
例えば「win:time_batch(10 sec, 5000L)」とした場合は5000ミリ秒=5秒だけずれるので以下のようになります。ちなみにミリ秒を%Lと表現するのはRubyのTime formatと同じです。
{"time":"2015/12/10 13:58:45","count":0}
{"time":"2015/12/10 13:58:55","count":1}
例えば○時30分から○時30分まで1時間単位でイベントを処理したいといった場合は60 * 30 * 1000 = 1800000で「win:time_batch(1 hour, 1800000L)」とすれば簡単に指定が可能です。
time-periodの第3引数
「view-win-time-batch」に解説があります。
第3引数にFORCE_UPDATEとSTART_EAGERというフロー制御を追加することができるとのこと。
要約するとイベントが実行された時に計測するためのデータが無い場合どうするかという制御のようです。
FORCE_UPDATEは強制的に項目で埋めて、START_EAGERはイベント開始前であっても空の結果を用意するとのこと。
空であっても出てきたフィールド名は表示したいみたいなときに使うものと思われます。
しかしこれは私の勉強不足のため、再現できず、詳細は不明です。
テストクエリ)win:time_batchに加え、COUNT文で同じものをカウントします。
SELECT name, age, COUNT(*) AS count FROM test.win:time_batch(1 min) WHERE age > 15 GROUP BY name, age
テストイベント
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \
echo '{"name":"jane", "age":20}' | norikra-client event send test && \
echo '{"name":"jane", "age":20}' | norikra-client event send test
出力イベント
[1450185248,{"count":1,"age":27,"name":"spike"}]
[1450185248,{"count":2,"age":20,"name":"jane"}]
2回流したjaneの項目はcountが2になっています。また、time_batchで60秒単位でイベントを処理しているため出力のタイムスタンプが同じ時刻になっています。
テストクエリ)第2引数に0Lを指定
SELECT name, age, COUNT(*) AS count FROM test.win:time_batch(1 min, 0L) WHERE age > 15 GROUP BY name, age
テストイベント
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \
echo '{"name":"jane", "age":20}' | norikra-client event send test && \
echo '{"name":"jane", "age":20}' | norikra-client event send test
出力イベント
[1450185660,{"count":1,"age":27,"name":"spike"}]
[1450185660,{"count":2,"age":20,"name":"jane"}]
タイムスタンプがunix epoch(UNIX時間)を基準に60秒単位になっています。
Externally timed batch window
基準となる時間を「イベントを流した時間」以外のものにします。
unix epochをフィールドに持っている場合は、そのフィールドを基準にイベントを集計することができます。
この指定を使えば、過去のデータであってもタイムスタンプに基づいて集計することができます。
書式)
win:ext_timed_batch(timestamp, 1 hours)
注意点として、時間は正しくソートされたものでなくてはならず、バラバラに渡されると破棄されます。詳しくは以下のサンプルを参照してください。
とりあえずサンプルとしてイベントの時間は「2015/12/00 00:00:00」としました。Unix epochで「1448841600」です。
テストクエリ
SELECT name, age FROM test.win:ext_timed_batch(timestamp * 1000, 1 min) GROUP BY name, age
テストイベント
# echo '{"timestamp":1448841600, "name":"spike", "age":27}' | norikra-client event send test && \
echo '{"timestamp":1448841600, "name":"jon", "age":25}' | norikra-client event send test && \
echo '{"timestamp":1448841660, "name":"ken", "age":25}' | norikra-client event send test && \
echo '{"timestamp":1448841610, "name":"ken", "age":22}' | norikra-client event send test
出力イベント
[1450240544,{"age":27,"name":"spike"}]
[1450240544,{"age":25,"name":"jon"}]
まず、ext_timed_batchでtimestampフィールドを基準にしています。timestampは秒単位なので、ミリ秒単位にするために1000を掛けています。
第2引数で「1 min」となっているので、一番初めのイベントのtimestamp「1448841600(2015/12/00 00:00:00)」を基準として、1分間データを計測します。
イベントの内、初めの2つは60秒位内なので正常に出力されています。
しかし、3つ目のイベントは1分経過しているのため、破棄されています。
続く4つ目のイベントは基準から10秒なので1分以内です。しかし3つ目のイベントで60秒以上経過したと判断されたため、そこで計測が終了します。そのため、4つ目のイベントは時間内にも関わらず出力されませんでした。
このように過去のデータを集計する場合はタイムスタンプの時間を正しくソートして流す必要があります。
Time length window (sliding time window)
カウント等を指定した時間だけまとめてイベント処理する。指定した時間を経過するとリセットされる。
指定した時間でまとめて出力するわけではなく、ビューを指定しない場合と同じように入力の数だけ出力するためスローが多いとメモリが枯渇するので注意。
書式
win:time( time-period )
テストクエリ
SELECT name, age, count(age) AS count FROM test.win:time( 1 min ) GROUP BY age
テストイベント
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \
echo '{"name":"jon", "age":25}' | norikra-client event send test && \
echo '{"name":"jon", "age":25}' | norikra-client event send test
(1分以上経過後に以下のイベント)
echo '{"name":"jon", "age":25}' | norikra-client event send test
出力イベント
[1450269185,{"count":1,"age":27,"name":"spike"}]
[1450269194,{"count":1,"age":25,"name":"jon"}]
[1450269202,{"count":2,"age":25,"name":"jon"}]
[1450269373,{"count":1,"age":25,"name":"jon"}]
基本的にイベントが渡された時間で即出力しています。
先頭から3つは初めのイベントから1分以内なので、カウントが追加されています。
しかし1分経過するとカウントがクリアされ、再び1からカウントされていることがわかります。
比較的少ないイベントで、○分以内に、○歳以上のユーサーが何人アクセスしたか計測する、といった用途に向いています。
Length (or Length batch) window
イベントのサイズに応じて集計、出力されます。
「イベントが○つ集まってから集計する」といった用途に使われます。サイズはサイズでもイベントの数で、バイトなんかのサイズではないので注意してください。
書式
win:length( size ) もしくは win:length_batch( size )
テストクエリ
SELECT name, age FROM test.win:length_batch( 2 )
テストイベント
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \
echo '{"name":"jon", "age":25}' | norikra-client event send test && \
echo '{"name":"ken", "age":15}' | norikra-client event send test
出力イベント
[1450274625,{"age":27,"name":"spike"}]
[1450274625,{"age":25,"name":"jon"}]
length_batchで2としているので、2つを同時に出力しています。
nameがkenのイベントは次のイベントがスローされると一緒に出力されます。
Unique
名前が示す通り指定したフィールドの値が一意の場合だけ出力します。
書式にあるexpressionの部分に一意にしたいフィールドを指定します。
例えばnginxのlogを渡す場合、ホストを登録すれば、1度拾ったホストは再度カウントされません。実質time_batch等と組み合わせて使用するものと思われます。(uniqueだけで使うと毎回拾うので意味が無い)
書式
std:unique( expression [, expression ... ] )
名前空間がwinからstdに変わっていますが、これもWindowの1つで、stdはStandard view setのことです。
Uniqueはその中でもUnique Windowと呼ばれるものです。
テストクエリ
SELECT name, age FROM test.win:time_batch(60 sec).std:unique(age)
テストイベント
# echo '{"name":"spike", "age":27}' | norikra-client event send test && \
echo '{"name":"jane", "age":25}' | norikra-client event send test && \
echo '{"name":"ken", "age":27}' | norikra-client event send test
出力イベント
[1450275726,{"age":25,"name":"jane"}]
[1450275726,{"age":27,"name":"ken"}]
3つ流しましたが、unique(age)で年齢が一意のものだけ表示するため、spikeの結果は消えて、kenだけが生きている。
被った場合は後半のイベントが有効になるようです。
と公式ページでは以上のViewが紹介されていますが、その他にも多くのビューが存在します。
詳しくは「Chapter 13. EPL Reference: Views」をご覧ください。
Field name escape
クエリの指定でフィールド名に使えるのは [_a-zA-Z0-9]+ だけです。SQLではドットやスペースは特別な意味を持つのでフィールド名の指定には使えません。
それらの文字はアンダースコアで補完することができるようです。
テストクエリ
SELECT user_name, age FROM test.win:time_batch(1 min)
テストイベント
# echo '{"user name":"spike", "age":27}' | norikra-client event send test
ERROR on norikra server: TypeError, can't dup NilClass
For more details, see norikra server's logs
と、エラーが出ます。auto fieldの関係かな?と推察して、まず「user_name」を流して型を確定してから「user name」を流すと正常に処理されました。
# echo '{"user_name":"spike", "age":27}' | norikra-client event send test && \
echo '{"user name":"John", "age":25}' | norikra-client event send test && \
echo '{"user.name":"ken", "age":20}' | norikra-client event send test
出力イベント
[1450278734,{"user_name":"spike","age":27}]
[1450278734,{"user_name":null,"age":25}]
[1450278734,{"user_name":null,"age":20}]
あれ?ふたつ目以降が正しく処理されてない。nullになってる。
原因は不明ですが、どうやら正しく値が取れないようです。そしてスペースやドットを持つフィールドはアンダースコアに変換したイベントを1度流して型を確定しないとエラーで受け付けない。
…ということで、クエリに使う文字列は素直に [_a-zA-Z0-9]+ にしておけ。ということで納得しておきます。
Container fields
ハッシュオブジェクトや配列にアクセスする方法。
ハッシュオブジェクトはドットで繋げる。
例)ハッシュオブジェクト
"user": {
"name": "tagomoris",
"email": "tagomoris@gmail.com",
},
クエリ例)
user.name // tagomoris
ではテストしてみます。
テストクエリ
SELECT user.name FROM test.win:time_batch(10 sec)
テストイベント
# echo '{"user": { "name": "tagomoris","email": "tagomoris@gmail.com" }}' | norikra-client event send test
出力イベント
[1449817825,{"user.name":"tagomoris"}]
配列
配列は配列の順序を$0で指定。後方参照のような形。二番目の項目は$1、三番目は$2といった感じ。
例)配列
"route": ["Shibuya", "Ohsaki", "Shinjuku", "Ikebukuro"]
クエリ例)
route.$1 // Ohsaki
ではこちらもテストします。
テストクエリ
SELECT route.$1 FROM test.win:time_batch(10 sec)
テストイベント
# echo '{"route": ["Shibuya", "Ohsaki", "Shinjuku", "Ikebukuro"]}' | norikra-client event send test && \
echo '{"route": ["Shibuya", "Shinjuku", "Ikebukuro"]}' | norikra-client event send test
出力イベント
[1449818014,{"route.$1":"Ohsaki"}]
[1449818054,{"route.$1":"Shinjuku"}]
Java methods, operators and functions
名前のとおりJavaのメソッドと、演算子等を使ってクエリを組み立てることもできる。
具体的には以下のクラスを使えるとのこと。
java.lang.* java.math.* java.text.* java.util.*
また関数も使えます。
CASE value WHEN v1 THEN r1 WHEN v2 THEN r2 [...] ELSE rr END CASE WHEN cond1 THEN r1 [...] ELSE rr END CAST( expression, type_name ) PREV(), CURRENT_TIMESTAMP() AVG(), COUNT(), MAX(), MIN(), SUM() and DISTINCT FIRST(), LAST(), MAXBY(), MINBY()
これはいちいちテストするより、Esperの用例を読むほうが早い。
EPL Reference: Operators
EPL Reference: Functions
Group by, Having, Order by, Limit
Group byによるグループ化、Havingによる絞り込み、Order byによる並び替え、Limitによる取得行の制限。
どれもSQLを扱う人にとっては、お馴染みです。恐らくnorikraを利用する上で最も利用頻度の高い関数。
集約(Aggregates)
| 平均偏差 | avedev([all|distinct] expression [, filter_expr]) |
|---|---|
| 平均 | avg([all|distinct] expression [, filter_expr]) |
| カウント | count([all|distinct] expression [, filter_expr]) |
| カウント(全フィールド) | count(* [, filter_expr]) |
| 最大値 | max([all|distinct] expression) |
| 最大値(制限付き) | fmax([all|distinct] expression, filter_expr) |
| 不明(理解不能) | maxever([all|distinct] expression) |
| 不明(理解不能) | fmaxever([all|distinct] expression, filter_expr) |
| 中央値 | median([all|distinct] expression [, filter_expr]) |
| 最小値 | min([all|distinct] expression) |
| 最小値(制限付き) | fmin([all|distinct] expression, filter_expr) |
| 不明(理解不能) | minever([all|distinct] expression) |
| 不明(理解不能) | fminever([all|distinct] expression, filter_expr) |
| 標準偏差 | stddev([all|distinct] expression [, filter_expr]) |
| 合計 | sum([all|distinct] expression [, filter_expr]) |
everの付いた集約の関数が理解できないが、恐らく今まで計測した中で最小・最大を返すのだと思われる。「今まで」がtime等で区切った範囲内なのか、計測開始から現在までなのかは検証してないので不明。
グループ化(Group-by)
特定のフィールドの値でグループ化するのに使われる。COUNT()にカウントする対象のフィールドを入れる。* で全てという指定もできる。AS <name>で別名(エイリアス)を付ける。
例えば以下のようにすれば、同じ年齢の男女別カウントが集計できる。
テストクエリ
SELECT sex, age, COUNT(age) AS count FROM test.win:time_batch(1 min) GROUP BY sex, age
テストイベント
# echo '{"user":"spike", "sex":"fem", "age":27}' | norikra-client event send test && \
echo '{"user":"ken", "sex":"fem", "age":27}' | norikra-client event send test && \
echo '{"user":"michael", "sex":"fem", "age":20}' | norikra-client event send test && \
echo '{"user":"Jane", "sex":"mal", "age":18}' | norikra-client event send test
結果Events
[1450316667,{"sex":"fem","count":2,"age":27}]
[1450316667,{"sex":"mal","count":1,"age":18}]
[1450316667,{"sex":"fem","count":1,"age":20}]
27歳のfemが2、20歳のfemが1、18歳のmalが1と正しく集計できています。
HAVING句
グループ化した上で条件を追加します。通常絞り込みはWHEREを使うが、GROUP BYはWHEREの後に実行されるのでGROUP BYの結果を絞り込むことはできない。
つまり、SQLと同じです。
テストクエリ
SELECT sex, age, COUNT(age) AS count FROM test.win:time_batch(1min) GROUP BY sex, age HAVING age = 27
テストイベント
# echo '{"user":"spike", "sex":"fem", "age":30}' | norikra-client event send test && \
echo '{"user":"ken", "sex":"fem", "age":27}' | norikra-client event send test && \
echo '{"user":"Jane", "sex":"mal", "age":27}' | norikra-client event send test
出力イベント
[1449894728,{"sex":"fem","count":1,"age":27}]
[1449894728,{"sex":"mal","count":1,"age":27}]
本来であればspikeの結果が表示されるが、ageを27に限定したので表示されない。
LIMIT句
取得する行数を制限するLIMIT句。
これもSQLと同じように使えます。通常はLIMIT 8 OFFSET 2といった指定の仕方をする。
LIMITはそのまま取得する行数を制限し、OFFSETは開始行を指定する。
OFFSETのカウントは取得行の先頭が0で、1とすると2行目から取得する。
「LIMIT 1, 2」とすることもできる。この表記の場合LIMITとOFFSETは反転する。そのため「LIMIT 2 OFFSET 1」と同じ意味になる。
テストクエリ
SELECT user FROM test.win:time_batch(60 sec) LIMIT 1, 2
テストイベント
# echo '{"user":"spike", "sex":"fem", "age":30}' | norikra-client event send test && \
echo '{"user":"ken", "sex":"fem", "age":27}' | norikra-client event send test && \
echo '{"user":"Jane", "sex":"mal", "age":27}' | norikra-client event send test
出力イベント
[1449896604,{"user":"ken"}]
[1449896604,{"user":"Jane"}]
LIMITでOFFSETが1なので、2行目から取得。LIMITが2としたので2行だけ出力されている。
ORDER BY句
並べ替え(ソート)を行うORDER BY。
フィールドの後にDESCを付ければ降順、ASCなら昇順となる。省略すると昇順になる。
複数ある場合は「age DESC, name ASC」とする。ageが降順になり、ageが同じの場合nameが昇順で並べ替えされる。
テストクエリ
SELECT user, age FROM test.win:time_batch(1 min) ORDER BY age
テストイベント
# echo '{"user":"spike", "sex":"fem", "age":30}' | norikra-client event send test && \
echo '{"user":"ken", "sex":"fem", "age":27}' | norikra-client event send test && \
echo '{"user":"Jane", "sex":"mal", "age":28}' | norikra-client event send test
結果Events
[1449915398,{"age":27,"user":"ken"}]
[1449915398,{"age":28,"user":"Jane"}]
[1449915398,{"age":30,"user":"spike"}]
ageの項目で昇順になっています。
rollup句、cube句、grouping sets句
GROUP BY ROLLUPは小計
テストクエリ
SELECT goods, sum( price ) FROM test.win:time_batch( 1 min ) GROUP BY ROLLUP( goods )
テストイベント
# echo '{"goods":"book", "price":100}' | norikra-client event send test &&\
echo '{"goods":"book", "price":180}' | norikra-client event send test &&\
echo '{"goods":"pen", "price":50}' | norikra-client event send test
出力イベント
[1449920810,{"goods":"book","sum(price)":280}]
[1449920810,{"goods":"pen","sum(price)":50}]
[1449920810,{"goods":null,"sum(price)":330}]
goodsごとにpriceが集計され、最後に小計されたpriceが出力されている。
cubeはクロス集計
grouping sets小計行とグループ化された集計行を区別。
norikraの例で言えば…、ちょっと使いみちを想像できませんw
JOINs and SubQueries
テーブル(Target)の結合もできます。しかし、fully-qualified field(完全修飾フィールド?)が必要。とのこと。
fully-qualified fieldは勉強不足のため、何のことか理解できませんでした。具体的にはTARGET.FIELDやALIAS.FIELDを指定することを意味するとのこと。つまり、一意なエイリアスを指定しないといけないということだろうか。
結合
とりあえずサンプルにある通り実行してみます。
テストクエリ
SELECT
a.user AS user,
a.sex AS sex,
b.age AS age
FROM user_sex.win:time_batch(60 sec) AS a,
user_age.win:time_batch(60 sec) AS b
WHERE a.user = b.user
AND b.user IN ('spike', 'ken', 'Jane')
GROUP BY a.user, a.sex, b.age
テストイベント
# echo '{"user":"spike", "sex":"fem"}' | norikra-client event send user_sex &&\
echo '{"user":"ken", "sex":"fem"}' | norikra-client event send user_sex &&\
echo '{"user":"Jane", "sex":"mal"}' | norikra-client event send user_sex &&\
echo '{"user":"spike", "age":18}' | norikra-client event send user_age &&\
echo '{"user":"ken", "age":25}' | norikra-client event send user_age &&\
echo '{"user":"Michael", "age":27}' | norikra-client event send user_age
出力イベント
[1449977286,{"sex":"fem","age":18,"user":"spike"}]
[1449977286,{"sex":"fem","age":25,"user":"ken"}]
SELECTで「AS user」と全ての要素に対してエイリアスを作成する。
FROMではsexとageの2つのターゲットを指定し、どちらにもエイリアスを指定している。
WHEREで「a.user」と「b.user」を結合するという結合条件を指定。
さらにANDで条件を追加してIN~で「b.user」の結合条件を追加で指定している。
最後「GROUP BY」でエイリアスを作成した項目を指定。
上の例ではターゲットageのuserフィールドの値がMichaelの項目は、WHERE INで条件に指定されていないため表示されていない。
また、WHERE INがなかったとしても、「WHERE a.user = b.user」で同じ項目を結合条件にしているため、aとbの両方に同じ項目が無いと表示されない。
つまり2つの条件で表示されていないことになる。
サブクエリ
サブクエリも使いこなすと非常に便利。
サブクエリ側はエイリアスを設定するも、メインクエリに関しては必要ないようです。
サブクエリには何らかのViewがないとエラーになるので注意。
テストクエリ
SELECT user, ( SELECT a.sex FROM user_sex.std:unique(user) AS a WHERE a.user = user_age.user ) AS sex, age FROM user_age
テストイベント
# echo '{"user":"spike", "age":18}' | norikra-client event send user_age
出力イベント
[1449978049,{"sex":null,"age":18,"user":"spike"}]
sexがnullになっている。これはサブクエリに指定したuser_sexが無いため。あくまでメインのターゲットはuser_ageなため、サブクエリのuser_sexが無くてもイベントは実行される。
そこで以下のようにする。
追加テストイベント
# echo '{"user":"spike", "sex":"fem"}' | norikra-client event send user_sex &&\
echo '{"user":"spike", "age":18}' | norikra-client event send user_age
出力イベント
[1449978102,{"sex":"fem","age":18,"user":"spike"}]
無事にサブクエリを取得することができました。
普通はメインクエリにwin:time_batch()などを指定して、時間内にメインクエリとサブクエリを受け付けるようにする。そうすることでサブクエリがnullになるのを防げる。
サブクエリの情報は1度取得すれば何回でも使い回し可能なようです。しかしメモリから溢れれば消えるはずなので、セットが前提の場合は時間内に取得できることを前提のlogに対して行う。
Fully-qualified field names and container fields
ターゲットの名前と、ハッシュの名前が被って、さらにハッシュ内のフィールドと、一般のフィールド名が被った場合は、どちらの項目かわからなくなる。
というよりも、この文章を読んでもわからないはずw
公式のサンプルを見たほうが理解が早いと思います。
以下の様な場合、Events.codeが指すものが、ハッシュ内のcodeなのか、TARGETがEventsのcodeなのか判断できない。
-- TARGET Name: Events
-- Data:
-- {
-- "Events": {"code":404, "path":"/"},
-- "code": 0,
-- }
SELECT
Events.code -- 404 ? 0 ?
FROM Events
そのような場合はハッシュ側でターゲット名を指定する。
SELECT Events.Events.code, -- 404 Events.Events.path, -- "/" code -- 0 FROM Events
これで区別が付く。
Filters/Patterns
フィルタとパターンも使える。
フィルタはWHERE INと似ており、取得する条件を指定する。○が○だったら、○が○と○の範囲内だったら、○に○が含まれなかったらなど、複雑な指定も可能。
パターンはWHEREと似ている。○が○以上だったらといった指定ができる。他にはタイマーで○時から○時まで実行といった指定も可能。
書式は多岐にわたるため以下を参照のこと。
その他のルール
Norikra独自のルール。
NorikraではSELECT * FROMといった指定は動作しません。使用するフィールドを指定する必要があります。これはスキーマレスなNorikraの制限です。
バッククォート「`」はサポートしません。スペースのある項目はアンダースコアで対応します。「user age」は「user_age」で指定できる。
イベントに必要なフィールドがあるかどうかはnorikraが自動で調べています。必要なフィールドのないイベントはnorikraが自動で無視します。
とのこと。
以上でNorikraの基本的な使い方を解説しました。
後半はうまい翻訳が思いつかず、手抜きですが、概要は理解していただけたと思います。
初めて触れるので難しそうに感じるだけで、一旦理解してしまえば、なんとも合理的な仕組みです。
Viewの扱いと、Norikraの書式さえ理解すれば、後はSQLとほぼ同じです。
「SQLライクにQueryを書こう」と解説される意味がわかります。
次は「fluentdとNorikraでDoS攻撃を遮断し、メールで通知する方法」を解説します。
 fluentdとNorikraでDoS攻撃を遮断し、メールで通知する方法
fluentdとNorikraでDoS攻撃を遮断し、メールで通知する方法 Norikraを1.3.1から1.4.0へアップデート
Norikraを1.3.1から1.4.0へアップデート Swatchでログを監視して、攻撃に合わせた対策を自動で実行する方法
Swatchでログを監視して、攻撃に合わせた対策を自動で実行する方法 iptablesをシェルスクリプトで設定していて動作が遅い場合の対処法
iptablesをシェルスクリプトで設定していて動作が遅い場合の対処法 サーバのログを監視するSwatchの導入方法と使い方を解説
サーバのログを監視するSwatchの導入方法と使い方を解説 whoisが暴走してCPU利用率が100%になった場合の対処法
whoisが暴走してCPU利用率が100%になった場合の対処法 「-j」オプションと「ccache」でコンパイル時間を400%高速化する方法
「-j」オプションと「ccache」でコンパイル時間を400%高速化する方法